Introduction
One day of data from a direct OPRA feed, October 18, 2006, was compressed
with nanex compression technology and
analysed in detail using a PowerEdge 1750 with dual 3.2GHz Xeon processors, 2
GB of RAM and Fujitsu 146GB SCSI hard disks on a 533MHz front side bus. Results
are shown for the time period 9:30am to 4:00pm which is the open and closing of
trading. Data before and after this period is not shown so that the most
important time periods can be scaled to show important details. In general, the
off-hours period has similar characteristics, but at much much lower and
negligible values.
Compression Bandwidth
Figure 1 below illustrates the incredible size reduction achieved by
nanex compression. Note how the
uncompressed OPRA data peaks in the 90mbps range, while the
nanex compressed data is easily
contained in 5 mbps. A standard T-1 Telco circuit is 1.5 mbps. Typical cable
modems are capable of between 2 and 6 mbps.
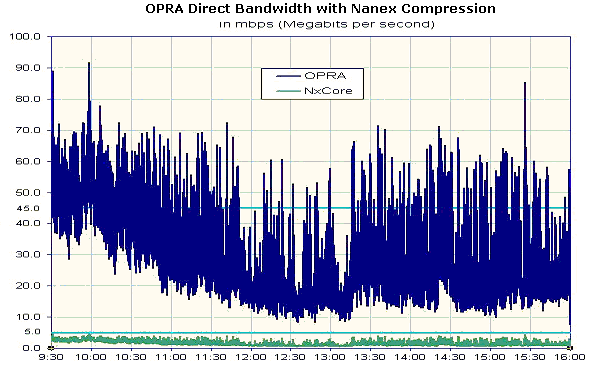
| Figure 1.
OPRA Direct Bandwidth with and without nanex
compression in 1 second intervals. |
Figure 2 below shows the same data in Figure 1, but plotted on a logarithmic
scale to show compression details. Note how closely the compressed stream
tracks the source data even though the data from opening rotation differs
significantly from data after that period. This is due to the fact that
nanex compression automatically and
quickly adapts to characteristic changes in the input stream; an important
feature for real-time financial data compression.
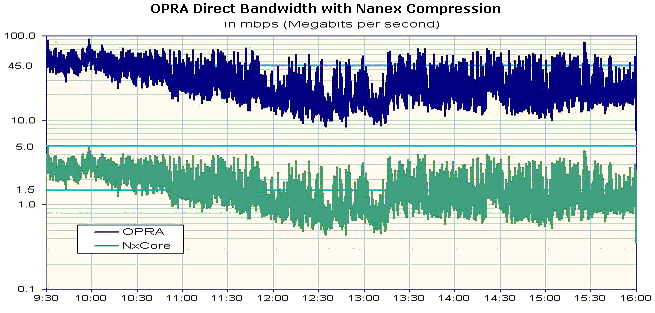
| Figure 2.
Same data from Figure 1, but plotted in Logarithmic scale for comparison
details. |
Figure 3 below shows the Compression Ratio which is simply the ratio of the
two lines in Figure 1. The compression ratio plotted over time clearly
illustrates the compression engine's ability to adapt to changing market
conditions. The inverse of the compression ratio subtracted from 1.0 and
expressed as a percentage is another common way to describe the amount of
compression. A Ratio of 20 to 1, shown simply as 20 in the graph below, would
become 95% (1.0 - 1/20)
| Figure 3. The
ratio of uncompressed message size to compressed message size |

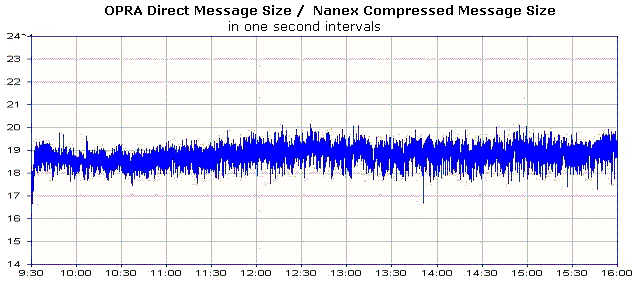
Packet Size
The majority of OPRA packets during trading hours are 991 bytes in length.
The second most common size is 941 bytes. The distribution of packets sizes
with significant occurrences is shown in Figure 4 below. In this chart,
note that there were approximately 42 million OPRA packets with a length of 991
bytes. Each OPRA packet contains multiple messages -- typically 14 to 15
quotes. A regular quote update is 65 bytes. If the NBBO (National Best
Bid/Offer) changes and that information is not part of the quote message, there
will be one or two 16 byte appendages for a total message size of 81 or 97
bytes respectively. Because OPRA packets cannot exceed 1000 bytes by
definition, and messages are never split between packets, there is always some
wasted transport space. As a general rule of thumb, the average OPRA quote
message size is 66 bytes.
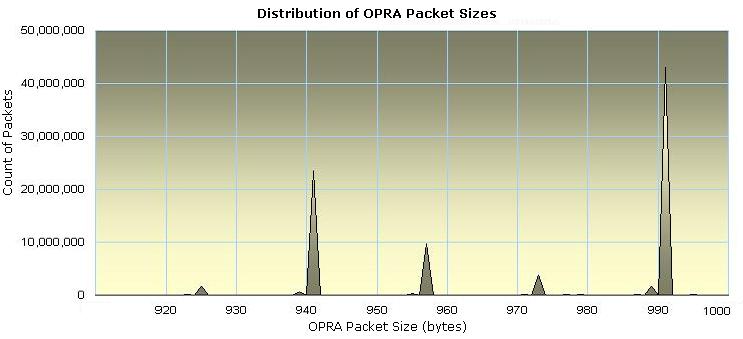
| Figure
4.Distribution of OPRA Direct Packet Sizes |
The distribution of nanex compressed
packet sizes is shown in Figure 5 below. The most common size is 52 bytes. The
very smooth bell shaped distribution is a characteristic of a well balanced
compression algorithm.
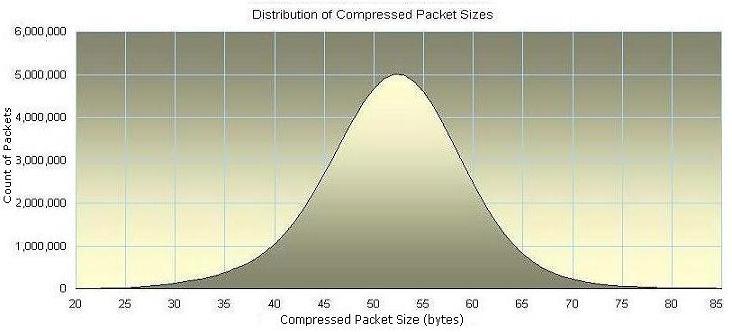
| Figure 5.
Distribution of nanex compressed OPRA
Direct packet sizes |
Compression Speed
Pay close attention to the units of time chosen to describe latency or the
speed of a critical algorithm. For real-time financial latency measurements,
the term "milliseconds" should have disappeared years ago, yet it's
common to find articles today describing "low latency" in terms of
milliseconds, or worse the term "sub-second" is used.
In one millisecond, there are 1,000 microseconds or 1 million nanoseconds. A 1
GHz machine has an instruction clock that ticks once per nanosecond or 1
million times per millisecond. In terms of cpu processing, a millisecond is a
very, very long period of time and many software instructions (a few hundred
thousand) can be executed during this interval.
Notes from the developer of nanex:
Speed was the most important feature during the development of the
[nanex] compression algorithm. It was
expected that there would be the usual trade-off between size and speed, that
is, you can have a fast algorithm but with average compression -- or you can
have great compression but at slow speeds. During the first few thousand hours
of developement, this was indeed the case.
But then a point came, around the 32nd major code branch, where both speed and
compression started improving together almost in a lockstep fashion. When the
compression first exceeded 90% [10 to 1],
and the speed was still well within
acceptable levels, there was considerable skepticism and a strong belief that
something was wrong: either the compression was missing something, or the tools
measuring the results were flawed (both of which had occurred many years
prior). Even after verifying the results several times using different methods,
with the algorithm continuing to improve to the point of dropping the output
size almost in half yet again, and speed even faster than before, I did not
accept the results completely.
It was only after months of consistent use and testing from that point, that I
came to accept it for what it was -- an algorithm that produced results far
beyond what I ever imagined or hoped for -- to the extent that I became
comfortable using the word "magic" when describing it.
Eric Scott Hunsader
July 2003
|
The time to compress one OPRA
packet is a remarkably steady 12 microseconds. The chart in figure 6 shows the
average compression time per packet in 1 second intervals. A typical OPRA
packet contains 15 quote messages.
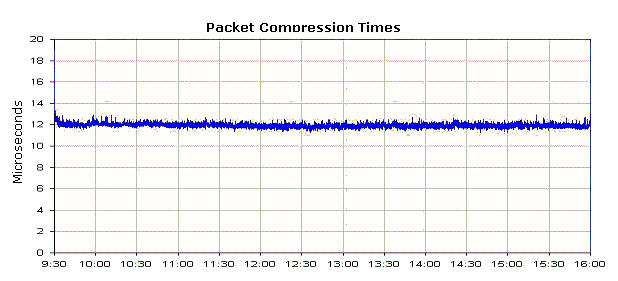
Figure 6.
Average time in microseconds to compress one OPRA packet at once second
intervals
|
Nanex compression can be used at the message level (it does not need to
read the entire packet to begin compressing). However, since most existing
software will processes OPRA data at the packet level, the analysis for this
paper focused on the packet level for easier comparison and understanding.
Nonetheless, figure 7 is presented below, showing the time spent compressing on
a message level. Note the scale is in nanoseconds.
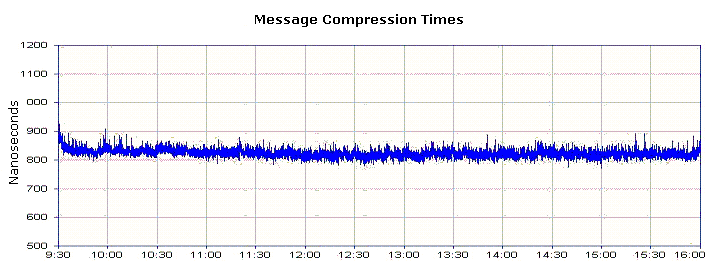
| Figure 7.
Average time in nanoseconds to compress 1 OPRA message at 1
second intervals |
Figure 8 below, compares cpu times other common operations for reference and
context. All operations were compiled for maximum performance and executed on
the same hardware. The exception is the entry for the Interrupt response time
of the newly released SLERT, Suse Linux Realtime, product which is included for
context. Note that nanex compression time is a little over two inline memory
copy operations.
| Figure 8.
Timings of common operations on a 991 byte OPRA packet.
|
Figure 9 shows the distribution of compression timings (in microseconds) for
one day of OPRA packets. Note the surprisingly narrow range of timing results
which is a rare and unexpected characteristic of compression algorithms in
general. Nanex compression time is
remarkably predictable: an invaluable benefit for time sensitive tasks. For
example, a task that accumulates multiple OPRA streams into one could better
determine whether there was enough time to compress and include another packet
in the outbound stream or not.
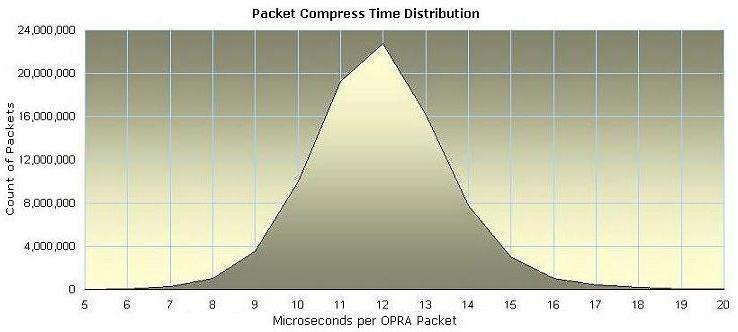
| Figure 9.
Distribution of time to compress one OPRA Packet. |
Another task that benefits from consistent and predictable compression
processing time is the determination of the maximum compression rate for a
given processor. Figure 10, shows the estimated maximum processing rate
in messages per second compared to the actual messages per second on October
18, 2006. The estimated maximum sustained rate is over 6 times the actual peak
rate.
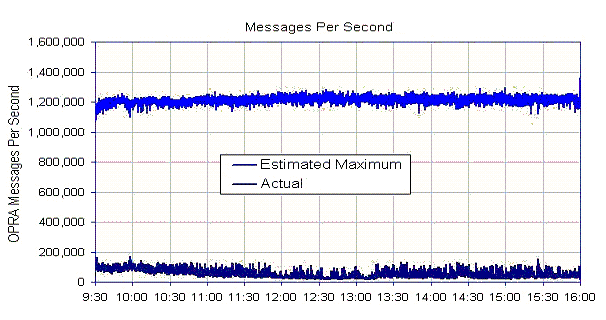
Figure 10.
Estimated maximum sustained processing rate in messages per second on a 3.2 GHz
Xeon processor (one thread).
|
Figure 11 presents a pie chart view of the distribution of packet
compression times. Note that 99.9% of packets are compressed in 20
microseconds or less, and 25% of packets are compressed in less than 10
microseconds.
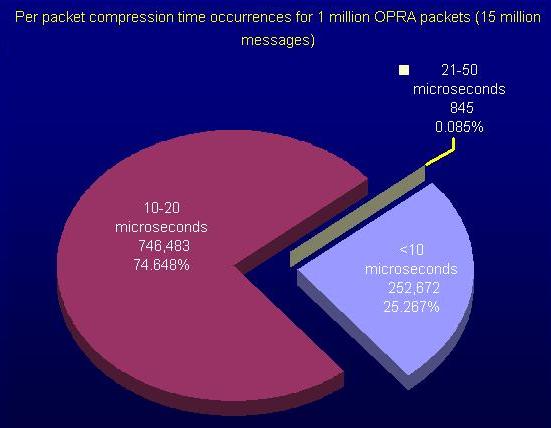
Figure 11.
Pie chart showing the distribution of packet compression times for the first 1
million OPRA packets on October 18, 2006.
|
As expected, the time to uncompress a packet is much shorter than the time to
compress it. Furthermore, uncompression time is even more constant and
predictable than compression time. Figure 12 shows the distribution of
uncompression times for one trading day. The most frequent uncompression time
is just 7 microseconds. The uncompression time would smaller by 2 microseconds
or more if the packets were uncompressed into a more efficient and ready to use
binary format rather than the ASCII format used in the OPRA specification.
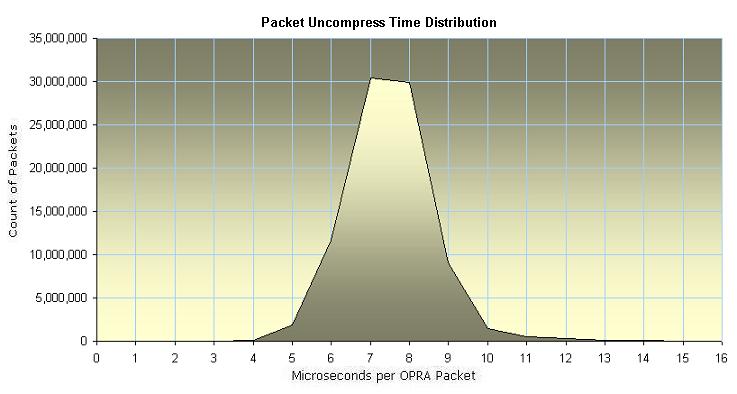
| Figure 12. Distribution of time
to uncompress one OPRA packet |
Comparison to WinZip
Compression algorithms used by programs such as Winzip, zlib, and gzip, are
not written for real-time streaming applications. They require a large
"window" or sample of data before compression begins. Having a large
sample of data to scan for redundancy is a significant advantage to compression
so it's not really a fair comparison. Nonetheless, Figure 13 shows the results
of compressing all the OPRA packets as if it were a single file compared to
nanex compression. The raw OPRA Direct
packets would require a file over 83 gigabytes. Winzip's compresses the
file to just under 20 gigabytes (20 billion bytes), yielding a ratio of just
over 4 to 1. Nanex compression produces
a file that is just 4.4 gigabytes, a ratio of 19 to 1.
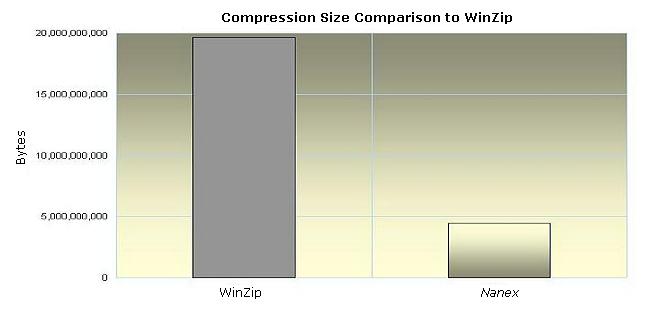
Figure 13. Comparison to Winzip
in size (bytes). Smaller is better.
|
Figure 14 shows the comparison of compression times between WinZip and
nanex compression on a day's worth of
OPRA packets in a file. Not only is nanex
compression 4 times smaller than WinZip, it's also nearly 4 times
faster.
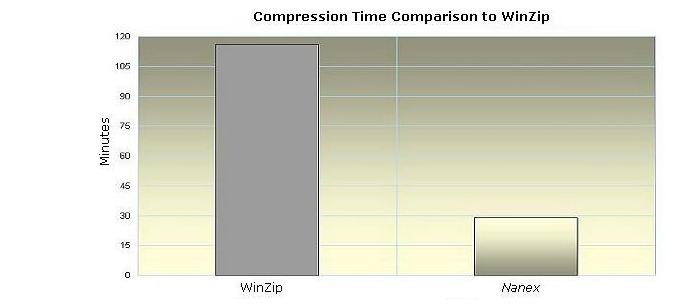
Figure 14.
Comparison to Winzip in time (minutes). Smaller is better.
|
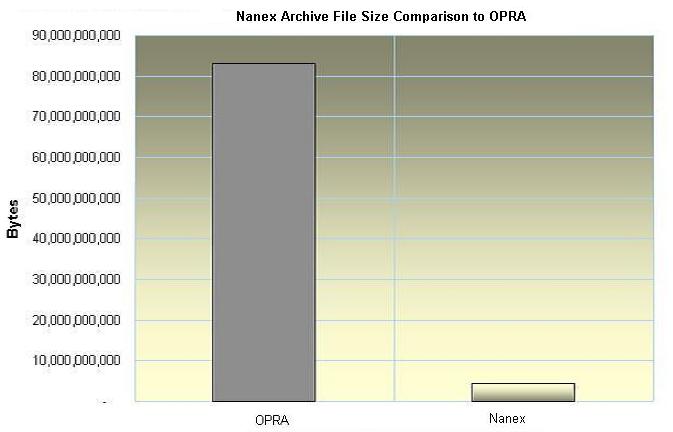
| Figure 15. Comparison of archived
packet file sizes. |
Conclusion
Nanex compression produces very
small packet sizes quickly and consistently. It can easily handle OPRA's rapid
growth in message update rates. With it's ability to automatically adapt to
changing input data, it is likely to continue to run for many years without
maintenance or changes to the algorithm.
|


